A hivatásos politikusi, a professzionális sajtóban megjelenő és a laikus online közbeszéd szociológiai elemzése automatizált szövegelemzés és kritikai diskurzuselemzés segítségével
Az NKFIH által támogatott kutatás (K-134428 azonosító alatt)
A projekt záró beszámoló értékelése: 10-es (kiváló). Részlet az értékelésből: “A kutatás egésze jelentős módszertani jellegű eredményekkel zárult, a résztvevők olyan szövegelemző megoldásokat fejlesztettek és kombináltak, melyek a legfrisebb NLP fejlesztésekre épülnek. A kutatás eredményei a társadalomtudományok széles köre és az üzleti terület számára egyaránt további specifikus kutatások során hasznosíthatók.”
Támogatási időszak: 2020. december – 2023. december
Alábbi beszámoló elkészülte: 2023. december 20.
Vezető kutató: Németh Renáta
Résztvevők: Barna Ildikó, Buda Jakab, Csigó Péter, Katona Eszter, Knap Árpád, Pólya Tibor (HUN-REN TTK), Rakovics Márton, Rakovics Zsófia, Sik Domonkos, Tóth Emese, Unger Anna
Összefoglaló
A nyilvánosság a modern képviseleti demokráciák sarokköve: nemcsak azért felelős, hogy a választók rendelkezésére álljon a megfontolt szavazáshoz szükséges információ, hanem azért is, hogy a közigazgatási rendszert ne csak jogi, hanem erkölcsi szempontból is felügyelje. Ebben az értelemben a nyilvánosság minőségétől függ azoknak a potenciális torzulásoknak és válságoknak az esetleges elhárítása, amelyek a demokratikus rendszerekben kialakulhatnak (Habermas 1975, 1998). Az online nyilvánosság kialakulása Magyarországon több hullámban is jelentős politikai átalakulásokkal és a politikai mező átrendeződésével esik egybe, ezért Magyarország különösen gazdag kontextust kínál a kutatás számára.
A kutatás a magyar nyilvánosság különböző szintjein – a hivatalos politikusi szférában, az online médiában és az online laikus nyilvánosságban – az utóbbi két évtized közbeszédének szociológiai elemzését adta, néhány kiemelt szempontra koncentrálva, elsősorban nagy szövegkorpuszok automatizált elemzésére építve. Kutattuk a politikai polarizáció nyelvi leképeződését, emlékezetpolitikai, kollektív identitással kapcsolatos témák és bizonyos közpolitikai témák diskurzusait.
Az online nyilvánosságban megjelenő digitális adatok elsősorban szöveges jellegűek. A feldolgozásukhoz szükséges eszközök csak a közelmúltban váltak hozzáférhetővé, a természetes nyelvfeldolgozás (NLP) elterjedésével, amely képes nagy mennyiségű szöveges adat szisztematikus, automatizált feldolgozására. Ezek az innovatív eszközök megfelelő mélységű eredményeket biztosítanak a szociológia számára is, ugyanakkor e tudományterület akkor fogja tudni kiaknázni az ezekben a változásokban rejlő lehetőségeket, ha képes megújítani kutatási kultúráját, miközben megőrzi kritikai reflexióit. Ezért volt küldetésünk egy olyan kutatás megtervezése, amely megmutatja, hogy az NLP hogyan illeszthető be szerves módon a hagyományos szociológiai módszerek eszköztárába.
A projekt az NLP több olyan eszközét használta vagy fejlesztette tovább (strukturális topikmodell, biterm topikmodell, dinamikus szóbeágyazás, dokumentum-beágyazás, keyness-elemzés), melyeknek nem vagy elvétve akadt korábban hazai társadalomkutatási alkalmazása. Az NLP-t a szociológia hagyományos szöveganalitikai eszköztárába illesztve kvalitatív eszközökkel kombináltuk. Eredményeink szerint e módszerekkel sikerrel tehető mérhetővé a politikai polarizáció és sikerrel képezhető le mind a nyilvánosságban megjelenő aktorok viszonyainak dinamikája, mind a nyilvánosság diskurzusaiban megjelenő témák keretezése, e keretezés változása, vagy bizonyos kulcsfogalmak jelentésváltozása.
Kutatásunk megítélésünk szerint mind a kutatási eredményeket és megjelent publikációkat, mind a megvalósított innovatív módszertani megközelítéseket, mind a kialakított új kutatási együttműködéseket tekintve sikeresen zárult, erről alább egy 2023. decemberi keltezésű összefoglaló.
Publikációk, disszemináció
A kutatás outputja többszörösen meghaladja a pályázatban vállaltakat. 48 tudományos publikáció született (összesen 9,6 impakt faktorral), ebből 11 már megjelent folyóiratcikk, 4 bírálat alatt. A megjelentek közül 7 nemzetközi cikk (ebből 3 D1 és 3 Q2 besorolású), 4 hazai cikk, 10 nemzetközi konferencia-előadás. A projektben készült egyik D1-es cikk (Barna-Knap szerzőségében) nyerte el 2023-ban a Magyar Szociológiai Társaság által az év legjobb szociológiai cikkének adott Polányi-díjat.
Az oldal alján található listán a négytucat (mtmt-ben is azonosítható) publikációnak csak egy válogatását adjuk, minden alprojektből csak a végleges, legmagasabb rendű közlés került feltüntetésre. Az Intersections folyóiratban a tervek szerint 2024-ben jelenik meg a kutatás témájában (‘Text as data – Eastern and Central European political discourses from the perspective of computational social science’) kutatócsoportunk tagjai által kezdeményezett és részben általuk vendégszerkesztett különszám, itt a kutatásból négy cikk van bírálat alatt.
Magunk is szerveztünk konferenciát és több konferencia-szekciót. 2021 nyarán az ISA RC33 bizottságának nemzetközi konferenciáján Barna Ildikó és Németh Renáta szervezett szekciót (‘Natural Language Processing: a New Tool in the Methodological Tool-Box of Sociology’ címmel), ahol több előadással szerepelt a kutatás is. 2022 szeptemberében Szöveg.Gép.Társadalom. címmel szerveztünk workshopot az ELTE Társadalomtudományi Karán, eredményeinket bemutatandó. 2023. júniusában a European Memory Politics Jean Monnet Network budapesti konferenciáján a ‘Methodological Sightseeing Tour in the World of Automated Text Analytics’ c. panel a bemutatkozásunk érdekében jött létre. 2023 októberében a Magyar Szociológiai Társaság Vándorgyűlésén szerveztek tagjaink (Rakovics Zsófia, Katona Eszter, Tóth Emese) szekciót ‘Természetes nyelv-feldolgozás a társadalomtudományokban’ címmel, ahol szintén több előadással szerepelt a kutatás.
A szélesebb közönséget több fórumon is igyekeztünk elérni, honlapunkon és facebook-oldalunkon kívül hat ismeretterjesztő előadást tartottunk: előadással és kerekasztal-részvétellel szerepeltünk a Kutatók Éjszakáján, a Táncsics Mihály Tehetséggondozó Kollégium és az Angelusz Róbert Társadalomtudományi Szakkollégium rendezvényein, megjelentünk a ConTEXT üzleti konferencián, továbbá Rakovics Márton 2023. szeptemberében az Eszéki Egyetem jogi karának meghívására tartott ismeretterjesztő előadást.
Kutatói utánpótlás-nevelés, új tudományos kapcsolatok
A kutatói utánpótlás-nevelésben is hasznosítani tudtuk a kutatást: 3 PhD-témát hirdettünk sikeresen, ezzel Buda Jakab, Rakovics Zsófia, Tóth Emese kapcsolódott be a kutatásba, témájukról alább találhatók részletek. Négy doktori és egy posztdoktori ÚNKP-ösztöndíj támogatta kutatás, szakdolgozatok és TDK-dolgozatok kapcsolódott a projekthez. Oktatott kurzusainkba is integráltuk a kutatás módszertanát és eredményeit.
A projekt előrehaladásával párhuzamosan olyan együttműködéseket sikerült létesíteni, melyek új interdiszciplináris kutatási irányként mélyebb elemzésekre adtak lehetőséget. Így Simonovits Bori szociálpszichológussal, Simonovits Gábor és Unger Anna politológussal, Balogh Péter humángeográfussal, Máté-Tóth András valláskutatóval és Pólya Tibor narratív pszichológussal dolgoztunk együtt társszerzőként.
Innovatív módszertani megoldások
További fontos hozadéka a projektnek az innovatív módszertani megközelítések kipróbálása, meghonosítása. Több olyan megközelítést és NLP-eszközt használtunk és részben fejlesztettünk tovább (strukturális topikmodell, biterm topikmodell, dinamikus szóbeágyazás, dokumentum-beágyazás, keyness-elemzés), melyeknek nem vagy elvétve akadt korábban hazai társadalomkutatási alkalmazása. Ezekről részletesebben alább a tudományos eredmények között.
A korpuszok összegyűjtése a projekt egyik legnagyobb kihívása volt. A kutatás alapkoncepciója szerint a nyilvánosság három szintjét (politikusi, média és laikus nyilvánosság) különböztettük meg, a korpuszokat is ennek megfelelően gyűjtöttük. A média-korpusz létrehozása volt a legnagyobb humánerőforrás-szükségletű feladat, négy mesterszakos gyakornok és három junior kutató dolgozott rajta a projekt első évétől kezdve, az ELTE BTK Digital Humanities (ELTE DH) Központjának szakmai együttműködésében. A korpusz építése az Indig és szerzőtársai által kidolgozott módszert (Indig B. et al, 2020) követve zajlott, a hivatkozott mű szerzői között is szereplő Knap Árpád irányításával. A korpuszépítés sajátossága, hogy gondosan metaadatolva, archívumra szerkesztve állítottuk össze a korpuszt, olyan technikai kihívásokat is megoldva mint a médiumonként eltérő szerkezet, a duplikátumok szűrése vagy a többoldalasság. A feladat 2022 közepére készült el, a korpuszok részei lettek egy olyan adattárnak, mely az ELTE DH gondozásában áll és tudományos kutatás céljára hozzáférhető a Zenodo platformon (https://zenodo.org).
A korpuszok feldolgozásához szükségünk volt egy egyezményes, a magyar nyelvre kidolgozott tisztítási és előfeldolgozási pipeline-ra. Ennek szakaszai: karakterek sztenderdizálása, a szövegek bizonyos szempontú szűrése, a szavak tisztítása és szűrése, a szavak szótövezése és egységesítése. A magyar nyelvre ezekre a feladatokra több nyelvészeti megoldás is létezik, ezek áttekintése után létrehoztunk egy egyezményes pipeline-t Pythonban a GitHub-on, amelyhez kérés esetén hozzáférést biztosítunk.
Tudományos eredmények
Módszertani eredmények
Téma: Az NLP felhasználása politikai polarizáció kutatására általában
Kapcsolódó publikáció: Németh, Renáta (2023): A scoping review on the use of natural language processing in research on political polarization: trends and research prospects. Journal of Computational Social Science
A cikk a projekt módszertani megalapozását nyújtotta. A 2010 óta a témában megjelent tanulmányok összegzését végezte el annak tisztázása érdekében, hogy az NLP-kutatási paradigma hogyan konceptualizálja és operacionalizálja a politikai polarizációt, követhető mintákat keresve, illetve azokat a kutatási fehér foltokat próbálva azonosítani, melyeket kutatásunk ambíciója szerint betölthet.
Téma: Hogyan mérhető a politikai polarizáció? Egy nyelvi megalapozású metrika javaslata
Kapcsolódó publikáció: Buda Jakab, Németh Renáta, Simonovits Bori, Simonovits Gábor (2022): The language of discrimination: assessing attention discrimination by Hungarian local governments. Language Resources and Evaluation
Projektünkben a polarizációt felügyelt gépi tanulási problémaként kezeltük, és azt vizsgáltuk, hogy pl. a különböző pártokhoz tartozó parlamenti képviselők beszédei alapján milyen hatékonysággal lehet a szerző párthovatartozását prediktálni, és ez a hatékonyság egyúttal a polarizáció általános mérőszámaként szolgált. Ebben ezt a módszert pilot-ként alkalmazó munkánkban még nem politikai szövegeken, hanem (vélt) roma, illetve nem-roma ügyfélnek írt önkormányzati hivatali email-ek szövegén mutattuk meg, hogy a szöveges adatokban emberi kódolás nélkül, automatizált módon is fel lehet fedezni a különbségeket, és hogy a gépi tanulás olyan megkülönböztető jegyeket is felismerhet, amelyeket az emberi kódolók esetleg nem ismernek fel. Tanulmányunk a polarizáció kutatásában elsődleges fontosságú feladatra, a modellek interpretációjára is kísérletet tett, vagyis azoknak a nyelvi jellemzőknek az azonosítására, amelyeket az algoritmus a megkülönböztetés mögött felismer.
Téma: Hogyan vizsgálható politikai kifejezések jelentésváltozása? Egy NLP-alapú megoldási javaslat
Kapcsolódó publikáció: Rakovics Zsófia (2022): Temporal Positive Pointwise Mutual Information (TPPMI) időbeli szóbeágyazási modell alkalmazásában rejlő lehetőségek demonstrálása – A miniszterelnöki beszédek szavainak jelentésváltozása. In Feledy A., Egle B. (szerk.): A ’Van új a nap alatt’ konferencia tanulmánykötete, Angelusz Róbert Társadalomtudományi Szakkollégium. A szerző Rakovics Mártonnal jelenleg nemzetközi publikáción dolgozik az eredmény bemutatására.
Projektünk egyik fő kérdésének, a politikai fogalmak jelentésváltozásának vizsgálatára kidolgozott módszert ismertet a cikk. A szemantikai dinamika kvantitatív vizsgálatát egy erre a célra kidolgozott időbeli szóbeágyazási modell segítségével javasolja elvégezni.
Téma: A felügyelt gépi tanulás szociológiai alkalmazási kihívásai
Kapcsolódó publikáció: Németh, Renáta (2021): A felügyelt gépi tanulás kihívásai a szociológiai alkalmazásokban. Metszetek – Társadalomtudományi folyóirat, Big Data különszám.
Az ipari/üzleti alkalmazásokban már sokszorosan bizonyított felügyelt gépi tanulás szociológiai alkalmazásai sajátos kérdéseket vetnek fel. A sajátosság oka, hogy ezekben az alkalmazásokban komplex fogalmak megtanulása az algoritmus feladata. A cikk e kihívásokról és megoldási lehetőségekről ad összefoglalót.
Téma: Az NLP intergrálhatósága a szociológiai módszertanba
Kapcsolódó publikáció: Németh, Renáta; Koltai, Júlia (2023): Natural language processing: The integration of a new methodological paradigm into sociology. Intersections: East European Journal of Society and Politics
Az NLP szociológiába való integrálása számos kihívással néz szembe. Az NLP a szociológián kívül intézményesült, míg a szociológia szaktudása a saját kutatási módszereire épült. Egy másik kihívás episztemológiai jellegű: a digitális adatok érvényességével és a prediktív és kauzális megközelítésekhez kapcsolódó különböző nézőpontokkal kapcsolatos. Dolgozatunkban néhány lehetséges megoldást kínáltunk e kihívásokra.
Tartalmi eredmények
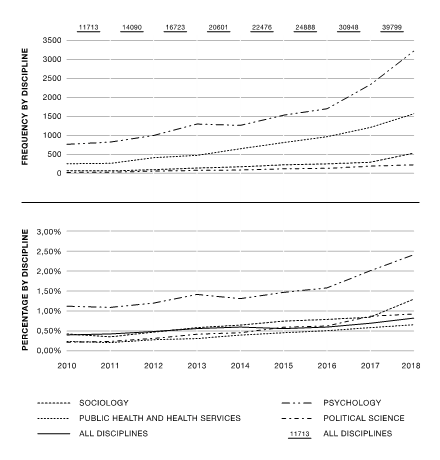
Kutatásunk során a 2000–2020 közötti magyar nyilvánosság hivatalos politikai, média és közösségi média rétegeiben folyó egyes diskurzusok feltérképezésére tettünk kísérletet (lásd az alábbi ábrát).

A politikai nyilvánosság hivatalos, sajtóbeli és laikus diskurzusokban elérhető rétegeit szövegkorpuszok segítségével közelítettük meg, míg a látens véleményklímát survey-ek másodelemzésével. Egyrészt felhasználtuk a Medián Közvélemény- és Piackutató Intézet által 2002 és 2008 között havi szinten végzett kutatásokat a magyar felnőtt népesség különböző aktuális eseményekhez fűződő ismereteiről és attittűdjéről. Másrészt a 2016-os European Social Survey, Attitudes to Climate Change, és az International Social Survey Programme 1993-as és 2020-as adatbázisát a környezeti fenntarthatósági attitűdök megismerésére.
Téma: Kortárs populizmus, bizonytalanság és félelem
Kapcsolódó publikációk:
- Sik Domonkos (2023): Populist Juggling with Fear: The Case of Hungary. East European Politics and Societies
- Boda Zsuzsanna, Rakovics Zsófia (2022): Orbán Viktor 2010 és 2020 közötti beszédeinek elemzése: A migráció témájának vizsgálata. Szociológiai Szemle
- Szalay Áron, Rakovics Zsófia (2023): Tuned to Fear – Analyzing Viktor Orbán’s State of the Nation Addresses, focusing on the enemy images identified in the National Consultation. Bírálat alatt
A cikkek témája a kortárs populizmus és a félelem mint eszköz kapcsolata. Az első cikk e vizsgálatot a késő modernitás elméleti keretében végzi el, a politikai cselekvőképesség beszűkülésének, a nyilvánosság újrakonfigurálásának és a bizonytalanság interiorizálásának hatását elemezve. Az empirikus vizsgálatot végző második és harmadik cikk kevert módszert használt, kritikai diskurzuselemzést és automatizált szövegelemzést (a célszavak súlyozott relatív gyakoriságára végezve statisztikai teszteket).
Téma: Emlékezetpolitika, identitáspolitika a média nyilvánosságában
Kapcsolódó publikációk:
- Barna, Ildikó; Knap, Árpád (2022): Analysis of the Thematic Structure and Discursive Framing in Articles about Trianon and the Holocaust in the Online Hungarian Press Using LDA Topic Modelling. Nationalities Papers.
- Knap Árpád, Bartha Diána, Barna Ildikó (2021): Trianon és a holokauszt emlékezetpolitikai jellegzetességeinek elemzése természetesnyelv-feldolgozás használatával. Szociológiai Szemle
- Máté-Tóth, András; Rakovics, Zsófia (2023): The discourse of Christianity in Viktor Orbán’s rhetoric. Religions
Két történelmi esemény, Trianon és a Holokauszt emlékezetpolitikai megközelítését vizsgálta az első két cikk a hazai sajtóban több tízezer szövegből álló korpuszok alapján, LDA topikmodellezés, illetve kvalitatív szövegelemzés segítségével. A cél nem csupán a látens tematikus struktúrák feltérképezése volt, hanem a politikai spektrum különböző oldalainak retorikája közötti főbb különbségek azonosítása is. Az egyik fő eredmény Bull és Hansen megközelítését követve az érzelmekhez való eltérő viszonyulásnak detektálta következményeit. Eszerint egyrészt az antagonista emlékezésben, tehát a szélsőjobboldali és kormánypárti médiában az érzelmek alapvető szerepet játszanak, míg a kozmopolita emlékezés, tehát a nem-kormánypárti médiában megjelenő retorika elvonatkoztat az érzelmektől. Ez a különbség jelentősen hozzájárul az antagonista emlékezés magyarországi sikeréhez, míg a baloldali-liberális oldal elveszíti az emlékezet és az identitáspolitika alakításának lehetőségét. Összességében Trianon az elemzett cikkekben a passzív áldozattá válással társul, míg a holokauszt kapcsán az egyes politikai oldalak narratívája még formálódik.
A harmadik cikk 1990 és 2022 között elhangzott tusványosi miniszterelnöki beszédekben vizsgálja kvantitatív és kvalitatív módszerekkel a kereszténység-felfogás változását, a kollektív identitással összefüggésben. Az NLP-módszerek közül szógyakoriság-elemzést és biterm topikmodellt használt.
Téma: A Parlament mint a hivatalos politikai nyilvánosság intézményének szöveganalitikai vizsgálata a 2000-2020-as időszakban
Kapcsolódó publikációk:
- Németh Renáta, Katona Eszter, Balogh Péter, Rakovics Zsófia, Unger Anna (2023): What else comes with a geographical concept beyond geography? Discourses related to the Carpathian Basin in the Hungarian Parliament (bírálat alatt)
- Sik Domonkos, Rakovics Zsófia, Németh Renáta (2023): Towards a culture of disrespect – topic modeling Hungarian parliamentary discourses (bírálat alatt)
- Rakovics Zsófia, Barna Ildikó (2023): The stages of Jobbik becoming a people’s party Analyzing the parliamentary speeches of Jobbik and the dynamic network of its politicians between 2010 and 2020 (bírálat alatt)
- Buda Jakab, Németh Renáta, Rakovics Zsófia (2023): Polarization as a Measure of Text Classification Performance – Evidence from the Hungarian Parliament 1998-2020 (befejezés előtt álló kézirat)
- Rakovics Zsófia, Unger Anna, Sik Domonkos, Németh Renáta, Barna Ildikó (2023): The changing institutional role of the Hungarian Parliament reflected in its changing language between 1998 and 2018 (befejezés előtt álló kézirat)
Ebben az alprojektben a hazai politikai pártok nyelvezetének változását, egymáshoz képesti távolságukat, a pártok szegmentációját elemeztük a politikusok nyelvezete alapján. Az első három cikk strukturális topikmodellt (STM) használ, ahol a párthovatartozás és az idő is metaváltozóként kezelhető, mely hatással van mind a detektált látens topikok prevalenciájára, mind azok tartalmára/keretezésére. A harmadik cikk emellett egy innovatív módszert, dokumentumbeágyazást is alkalmaz a politikusok hálózatának megrajzolásához. A negyedik cikk a polarizációt mint felügyelt gépi tanulási problémát közelíti meg, és azt elemzi, hogyan változik az egyes parlamenti ciklusokra illesztett predikciós modellek hatékonysága az időben előre haladva. Végül az utolsó cikk keyness-elemzést végzett, azzal a céllal, hogy azonosítsa azokat a legfontosabb kulcsszavakat, amelyek a legjobban jellemzik az egyes pártokat ill. leginkább megkülönböztetik őket egymástól, majd Jaccard-hasonlósági mérték segítségével számszerűsítettük az időbeli változást általában a parlamenti beszédek, illetve az egyes pártok esetében.
A Parlament intézményi szerepének változását jellemzi e cikkek egy része. Így Sik és társai (2023) elemzése szerint a gazdaságpolitikák fokozatosan kivonultak a parlamenti ellenőrzés alól, a válságdiskurzusok teret nyertek, a demokratikus állampolgári kultúra eljárási és kommunikációs mutatói csökkentek. A parlamenti nyilvánosság azoknak a szemantikáknak és diszkurzív stílusoknak a gyengülését jelezte, amelyek a deliberatív demokráciával voltak rokoníthatóak. Rakovics és társai (2023) eredményei ezt az eredményt árnyalja: eszerint a parlamenti beszédek nyelvezete egyre bürokratikusabbá válik, és bizonyos értelemben a parlament jelentősége is csökken az évek során.
A cikkek másik része a pártok távolságának erősödő tendenciájára és ennek jellegére mutat rá. Buda és társai (2023) a nyelvi polarizáció egyre erősödő jelenlétét mutatták ki öt parlamenti ciklus összevetésében. Németh és társai (2023) a parlamenti beszédek egy alkorpuszán, a Kárpát-medencével kapcsolatos diskurzust tekintve mutatott ki erősen eltérő keretezést a politikai ideológia szerint; pl. míg a baloldali-liberális felszólalásokban kevésbé személyes hangon beszélnek, intézményekre, érdekekre és stratégiára utalnak, addig a Fidesz és más jobboldali-konzervatív pártok képviselői saját közösségük képviseletében beszélnek, értékekre, érzelmekre és kultúrára hivatkozva. Az eredmények megerősítik azt az általános megfigyelést, hogy a baloldali-liberális blokk hisz az egyetemes racionális konszenzusban, miközben figyelmen kívül hagyja a politika affektív dimenzióját; ezzel szemben a jobboldali-konzervatív blokk kollektív identitást kínál, amelyhez az emberek értékeket és érzelmeket kapcsolnak.
Míg a pártok távolodnak egymástól, addig adott párton belül egységesedés figyelhető meg – ez a konklúziója Rakovics és Barna (2023) egyetlen pártra, a Jobbikra fókuszáló elemzésének. A párt politikusainak parlamenti felszólalásainak elemzésével vizsgálja a cikk kommunikációjukat és szervezetük fejlődését. A párttagok dinamikus hálózata és beszédeik tematizáltsága alapján a kezdetben igen heterogén párt homogenizálódása volt megfigyelhető, a harmadik parlamenti ciklusban ez egyfajta professzionalizálódással járt együtt.
Téma: A fenntarthatóság mint közpolitikai téma a hazai politikai nyilvánosságban
Tóth Tímea Emese, a kutatócsoportban dolgozó doktori hallgató végzett Németh Renáta és Kocsis János Balázs témavezetésével a témában kutatásokat, ÚNKP-ösztöndíjat is elnyerve vele három egymást követő alkalommal. Kapcsolódó publikációk:
- Tóth, Tímea Emese (2022): Analysis of the Twitter Discourse on Sustainability Using Natural Language Processing. Education of Economists & Managers
- Hogyan alakította a COVID-19 pandémia a fenntarthatósági diskurzust a laikus nyilvánosságban? Narratívák és kommunikációs stratégiák. (befejezés előtt álló kézirat)
- A fenntarthatóság politikai polarizáció által keretezett narratív lehetőségei az online média felületeken (bírálat alatt)
- A magyar lakosság környezetvédelmi attitűd-változásainak elméleti és módszertani dilemmái. Az ISSP 1993 és 2020 adatfelvételek összehasonlításának eredményei (folyamatban lévő ÚNKP kutatás)
E kutatások célja az online média különböző rétegeiben (a Twitter laikus nyilvánosságában, a hazai online sajtóban) folyó fenntarthatósági diskurzus tartalmi leképezése és a véleményklíma dinamikájának, meghatározó faktorai alakulásának feltérképezése survey-ek komparatív elemzése révén. Módszertani megoldásként LDA topikmodellezést és strukturális topikmodellt alkalmazva a korpuszok látens témáinak azonosítására, és szentimentelemzést az érzelmi viszonyulások feltárására. A strukturális topikmodell itt a fenntarthatósági témák keretezésének politikai polarizáltságának megragadására is képes, a politikai álláspontot mint metaadatot használva.
A támogatás hosszabb távú hasznosulásáról
A támogatás számos új projekthez vezetett: TDK-kutatások, doktori és posztdoktori ÚNKP-kutatások valósultak meg a kutatáshoz kapcsolódó altémákkal. A kutatásban megszerzett módszertani tapasztalatoknak köszönhetően sikeresen pályáztunk a Társadalmi Innovációs Nemzeti Laboratórium által támogatott két egyéves kutatást (2021, 2023) és a CELSA projektben támogatott kétéves kutatást a Leuveni Katolikus Egyetem kutatóival (2023. szeptemberben indulva).
Több tudományos együttműködés jött létre a projektnek köszönhetően, a téma komplexitásából adódóan igazi interdiszciplináris jelleggel: az ELTE BTK Digital Humanities központ (számítógépes nyelvészet), a TU Wien (informatika), az ELTE TTK (társadalomföldrajz) és a HUN-REN TTK (narratív pszichológia) kutatóival. Az így megkezdett új interdiszciplináris kutatási irányok reményeink szerint inspiráló szakmai lehetőségekhez és jövőbeni új tudományos eredményekre vezetnek.
A projektben kidolgozott kutatási infrastruktúra (szakértelem és módszerek), illetve eredmények újabb sikeres kutatási pályázatok kiindulópontjai lehetnek – ezeken a pályázatokon jelenleg is aktívan dolgozunk.
Kapcsolódó doktori kutatások
Doktori hallgató: Rakovics Zsófia
Témavezetők: Németh Renáta, PhD, Sik Domonkos, PhD
Doktori hallgató: Tóth Emese
Témavezető: Kocsis János Balázs, PhD
Doktori hallgató: Buda Jakab
Témavezető: Dr. Németh Renáta
A projekt keretében megjelent közlemények (válogatott lista)
Csomor, Gábor; Simonovits, Borbála; Németh, Renáta: Hivatali diszkrimináció?: Egy online terepkísérlet eredményei, Szociológiai Szemle, 2021
Katona, Eszter, Németh, Renáta: Automatizált szöveganalitika a korrupció kutatásában, SOCIO.HU: TÁRSADALOMTUDOMÁNYI SZEMLE, 2021
Barna, Ildikó; Knap, Árpád: Analysis of the Thematic Structure and Discursive Framing in Articles about Trianon and the Holocaust in the Online Hungarian Press Using LDA Topic Modelling., NATIONALITIES PAPERS, 2022
Boda Zsuzsanna, Rakovics Zsófia: Orbán Viktor 2010 és 2020 közötti beszédeinek elemzése: A migráció témájának vizsgálata, Szociológiai Szemle, 2022
Buda Jakab, Németh Renáta, Simonovits Bori, Simonovits Gábor: The language of discrimination: assessing attention discrimination by Hungarian local governments, Language Resources and Evaluation, 2022
Buda, Jakab ; Simonovits, Bori ; Németh, Renáta: Hivatali diszkrimináció? – Figyelemdiszkrimináció mérése természetes nyelvfeldolgozással, Konferencia előadás, Szöveg.Gép.Társadalom – Társadalmi viszonyok megragadása szöveges adatok számítógépes elemzésével., Az ELTE Reserach Center for Computational Social, 2022
Knap Árpád, Bartha Diána, Barna Ildikó: Trianon és a holokauszt emlékezetpolitikai jellegzetességeinek elemzése természetesnyelv-feldolgozás használatával, Szociológiai Szemle, 2022
Knap, Árpád ; Tóth, Tímea Emese ; Barna, Ildikó: Érzelmek megjelenése a Trianoni békeszerződéssel és a holokauszttal kapcsolatos cikkek szóbeágyazásaiban, az érzelmek automatizált detektálásának lehetséges eszközei, Konferencia előadás, Szöveg.Gép.Társadalom – Társadalmi viszonyok megragadása szöveges adatok számítógépes elemzésével., Az ELTE Reserach Center for Computational Social, 2022
Németh Renáta: A szakterületi tudás (domain knowledge) szerepe az adattudomány társadalomkutatási alkalmazásaiban, In: Loncsák, Noémi; Szabó-Tóth, Kinga (szerk.) Szociológiai tudás és közjó : absztraktkötet. Miskolc, Magyarország : Magyar Szociológiai Társaság (2022) 247 p. pp. 158-15, 2022
Németh Renáta: Nyelvi polarizáció kutatása NLP-vel: módszertani kihívások (általánosíthatóság, oksági tévkövetkeztetés), Gép.Társadalom – Társadalmi viszonyok megragadása szöveges adatok számítógépes elemzésével., Az ELTE Research Center for Computational Social Science konferenciája. 2022.
Rakovics Zsófia: Migrációs diskurzusok elemzése a parlamenti felszólalások alapján, Magyar Szociológiai Társaság (MSZT) Vándorgyűlés, Szociológiai tudás és közjó, Miskolci Egyetem, 2022. október 14-15., 2022
Rakovics Zsófia és Rakovics Márton: Parlamenti felszólalások elemzése dokumentumbeágyazással. Szöveg.Gép.Társadalom – Társadalmi viszonyok megragadása szöveges adatok számítógépes elemzésével, Szöveg.Gép.Társadalom – Társadalmi viszonyok megragadása szöveges adatok számítógépes elemzésével., Az ELTE Reserach Center for Computational Social Science konferenciája, 2022
Rakovics, Zsófia; Rakovics, Márton: Semantic evolution of words in Hungarian PM Viktor Orbán’s speeches using a temporal word embedding model focusing on the issue of migration, Konferencia megjelenés (poszter) a 8. Nemzetközi Számítógépes Társadalomtudomány Konferencián (8th International Conference on Computational Social Science IC2S2). 2022., 2022
Sik Domonkos: A poiesis autonómiája – a társadalmi struktúrák és a diszkurzív lehetőségterek kölcsönhatása, A társadalomelmélet alapkérdései – konferencia a Nemzeti Közszolgálati Egyetemen, 2022. november 3-4., 2022
Tóth Tímea Emese: Analysis of the Twitter Discourse on Sustainability Using Natural Language Processing, Education of Economists & Managers, 2022
Tóth Tímea Emese: A fenntarthatósággal kapcsolatos Twitter-diskurzus elemzése a természetes nyelvi feldolgozás módszerével, “Kit érdekel még a szociológia?” – konferencia, Társadalomtudományi Kutatóközpont, 2022.06.03., 2022
Tóth Tímea Emese: Hogyan definiálta újra a COVID-19 pandémia a fenntarthatóság fogalmát a laikus nyilvánosságban? Narratívák és kommunikációs stratégiák, Eötvös Loránd Tudományegyetem. 2022.08.31., 2022
Tóth Tímea Emese: Minden, amit a fenntarthatóságról és klímaváltozásról tudni akartál, de nem merted megkérdezni, Táncsis Mihály Tehetséggondozó Kollégium Budapest. 2022.03.09., 2022
Barna, Ildikó; Németh, Renáta; Pólya, Tibor; Berbekár, Réka: Examining the Different Political Sides’ Memorialization of Using Tools of Natural Language Processing and Narrative Psychology, XX. ISA World Congress of Sociology, 2023. jún. 25-júl. 1, 2023
Katona, Eszter; Németh, Renáta: Carpathian Basin-related topics in Hungarian parliamentary speeches. A concept related to Hungary’s self-definition, CENTRAL Workshop: Notion and Construction of Victimhood in Central East and Southeast Europe. 2023. február 8-10. Bécs, 2023
Máté-Tóth, András; Rakovics, Zsófia: The discourse of christianity in Viktor Orbán’s rhetoric, Religions, 2023
Németh Renáta: A scoping review on the use of natural language processing in research on political polarization: trends and research prospects, Journal of Computational Social Science , 25 p., 2023
Németh Renáta, Katona Eszter, Balogh Péter, Rakovics Zsófia, Unger Anna: What else comes with a geographical concept beyond geography? Discourses related to the Carpathian Basin in the Hungarian Parliament, bírálat alatt, 2023
Németh Renáta, Rakovics Zsófia: A természetesnyelv-feldolgozás néhány szociológiai alkalmazásáról, SciComp 2023 konferencia. Budapest, 2023. november 7-8., 2023
Németh, Renáta; Barna, Ildikó; Pólya, Tibor: Az NLP kísérleti kombinálása narratív pszichológiai gépi elemzővel – A trianoni békeszerződés a magyar online médiában a 100. évfordulón, A Magyar Szociológiai Társaság 2023. évi vándorgyűlése, Corvinus Egyetem, Budapest, 2023., 2023
Németh, Renáta; Buda, Jakab; Simonovits, Bori: The Language of Discrimination: Assessing Attention Discrimination By Hungarian Local Governments Using Machine Learning, XX. ISA World Congress of Sociology, 2023. jún. 25-júl. 1., 2023
Németh, Renáta; Buda, Jakab; Simonovits, Bori: Who knows it better? The task of detecting discrimination using human coding vs. text mining, EuMePo (European Memory Politics) Jean Monnet Network Conference, Budapest, 2023. június 15., 2023
Németh, Renáta; Koltai, Júlia: Natural language processing: The integration of a new methodological paradigm into sociology, INTERSECTIONS: EAST EUROPEAN JOURNAL OF SOCIETY AND POLITICS 9: 1 pp. 5-22., 2023
Rakovics Zsófia: Memory politics in the Hungarian Parliament, CENTRAL workshop: Notion and Construction of Victimhood in Cenral East and Southeast Europe. Vienna, 8-10 February, 2023, 2023
Rakovics Zsófia: Investigating language- and political polarization through two decades of parliamentary speeches, XX. ISA World Congress of Sociology. 25 June – 1 July, 2023, 2023
Rakovics Zsófia: Investigating dynamic social networks of politicians constructed by the similarity of their speeches, XX. ISA World Congress of Sociology. 25 June – 1 July, 2023, 2023
Rakovics Zsófia: Szóbeágyazások és nagy nyelvmodellek társadalomtudományi alkalmazásának példái, conTEXT 2023 – Change the game? Budapest, CEU, 2023. november 14., 2023
Rakovics Zsófia, Barna Ildikó: The stages of Jobbik becoming a people’s party Analyzing the parliamentary speeches of Jobbik and the dynamic network of its politicians between 2010 and 2020, bírálat alatt, 2023
Rakovics Zsófia, Rakovics Márton: Language- and political polarization of parliamentary speeches between 1998-2020, 9th International Conference on Computational Social Science. Copenhagen, 17-20 July, 2023, 2023
Sik Domonkos, Rakovics Zsófia, Németh Renáta: Towards a culture of disrespect – topic modeling Hungarian parliamentary discourses, bírálat alatt, 2023
Sik, Domonkos: Populist Juggling with Fear: The Case of Hungary, EAST EUROPEAN POLITICS AND SOCIETIES 37 : 4 pp. 1291-1313. , 23 p, 2023
Szalay Áron, Rakovics Zsófia: Tuned to Fear – Analyzing Viktor Orbán’s State of the Nation Addresses, focusing on the enemy images identified in the National Consultation, bírálat alatt, 2023
Tóth Tímea Emese: Hogyan kapcsolódik a koronavírus és a fenntarthatóság az online média kommunikációjában?, Táncsics Mihály Tehetséggondozó Kollégium. Budapest. 2023.04.25., 2023
Tóth Tímea Emese: A fenntarthatóság politikai polarizáció által keretezett narratív lehetőségei az online média felületeken, Eötvös Loránd Tudományegyetem. 2023.08.31., 2023
Tóth Tímea Emese: Hogyan hatott a koronavírus-járvány a fenntarthatósági diskurzusra?, Magyar Szociológiai Társaság Éves Vándorgyűlése 2023. Válságról válságra. Budapest. 2023.11.18., 2023
Verebes Ingrid, Rakovics Zsófia: A család diskurzusának alakulása az 1998-2020 közötti parlamenti felszólalásokban, MSZT 2023. évi vándorgyűlés. Budapest, BCE, 2023. november 17-18., 2023