A sociological analysis of the official, media-based and lay online public sphere using automated text analytics and critical discourse analysis
A research project supported by NKFIH (National Research, Development and Innovation Office) (K-134428)
Rating of the final project report: 10 (excellent). Excerpt from the evaluation: ‘The research as a whole produced significant methodological results, with participants developing and combining text analysis solutions based on the latest NLP developments. The results of the research can be used for further specific research in a wide range of social sciences as well as in the business domain.”
Period of support: December 2020-December 2023
Date of the report: 20. December 2023.
Principal Investigator: Renáta Németh
Participants: Ildikó Barna, Jakab Buda, Eszter Katona, Árpád Knap, Tibor Pólya (HUN-REN TTK), Márton Rakovics, Zsófia Rakovics, Domonkos Sik, Emese Tóth, Anna Unger
Summary
The public sphere is the cornerstone of modern representative democracies: it is responsible not only for providing the voters with the necessary information for a deliberate vote but also to keep the administrative system in check not solely from a legal but also from a moral standpoint. In this sense, the prospect of averting those potential distortions and crises which may emerge in democratic systems depend on the quality of the public sphere (Habermas 1975, 1998). The emergence of the online public sphere overlaps with several waves of significant political transformations and reconfigurations of the political field in Hungary. Therefore, Hungary is a particularly rich context for this research.
The research provided a sociological analysis of the public discourse of the last two decades at different levels of the Hungarian public sphere – the official political sphere, the online media and the online lay public – focusing on a few key aspects, mainly based on the automated analysis of large text corpora. We have explored the linguistic representation of political polarization, the discourse of memory politics, collective identity issues and certain public policy topics.
Digital data produced in online public spheres are primarily textual. Such data require analytical tools, which became accessible only recently with the emergence of the field of Natural Language Processing (NLP) capable of processing large-scale textual data in a systematic, automated way. These innovative tools provide suitable depth in results for sociology (Németh and Koltai, 2020). Sociology will exploit the potential of these changes if it can renew its research culture while preserving its critical reflections. Hence it was our mission to plan a research that shows how NLP can be integrated in an organic way into the toolbox of traditional sociological methods. To reach this aim, we plan to combine automated text analytics with not only qualitative discursive analysis but also traditional quantitative statistical methods.
The project used or further developed several tools of NLP (structural topic model, biterm topic model, dynamic word embedding, document embedding, keyness analysis), which had no or only occasionally been used in Hungarian sociological research. NLP was integrated into the traditional text analytical tools of Sociology and combined with qualitative tools. According to our results, these methods can successfully measure political polarization and map the dynamics of relations between actors in the public sphere, the framing of topics in public discourse, changes in framing, or changes in the meaning of certain key concepts.
We consider our research to has been successfully completed in in terms of both the research results and publications, the implemented innovative methodological approaches and the established new research collaborations Below is a summary dated December 2023.
Publications, disseminations
The output of the research is several times higher than what was committed in the application. 48 scientific publications have been produced (with a total impact factor of 9.6), of which 11 have been published in peer-reviewed journals and 4 are under review. Of these, 7 international articles (3 D1 and 3 Q2), 4 national articles, 10 international conference presentations. One of the D1 articles of the project (authored by Barna-Knap) won the Polányi Prize for the best sociological article of the year in 2023, awarded by the Hungarian Sociological Association.
The list at the bottom of this page provides only a selection of the four dozen publications (also identifiable in MTMT), with only the final, highest-ranking publication from each sub-project. A special issue of the journal Intersections on the topic of our research (‘Text as data – Eastern and Central European political discourses from the perspective of computational social science’), initiated and partly guest-edited by members of our research team, is scheduled to appear in 2024, with four articles from the research under review.
We have also organised a conference and several conference sessions. In the summer of 2021, Ildikó Barna and Renáta Németh organised a session at the international conference of the ISA RC33 committee (‘Natural Language Processing: a New Tool in the Methodological Tool-Box of Sociology’), where we also presented our research. In October 2023, our members (Zsófia Rakovics, Eszter Katona, Emese Tóth) organized a session at the Hungarian Sociological Society’s Annual Meeting entitled ‘Natural Language Processing in the Social Sciences’, where we also presented our research.
We have reached out to the wider public in various forums, and besides our website and Facebook page, we have held six educational presentations: we gave a presentation and participated in a roundtable at the Night of Researchers, the Mihály Táncsics Talent College and the Róbert Angelusz Social Sciences College, we participated in the ConTEXT business conference, and Márton Rakovics gave a lecture at the invitation of the University of Osijek at the Faculty of Law in September 2023.
Research recruitment education, new scientific relationships
We were also able to use the research in the training of young researchers: 3 PhD theses were successfully advertised, with Jakab Buda, Zsófia Rakovics, Emese Tóth joining the research, details of their topics can be found below. Four doctoral and one postdoctoral New National Excellence Program (now University Research Scholarship Program, EKÖP) supported research, theses and TDK (Scientific Student Council) theses were linked to the project. We also integrated the research methodology and results into our taught courses.
As the project has progressed, collaborations have been established that have allowed for deeper analysis as a new interdisciplinary research direction. Thus, we worked with social psychologist Bori Simonovits, political scientists Gábor Simonovits and Anna Unger, human geographer Péter Balogh, religious researcher András Máté-Tóth and narrative psychologist Tibor Pólya as co-authors.
Innovative methodological solutions
Another important output of the project is the testing and introduction of innovative methodological approaches. Several approaches and NLP tools were used and partly developed (structural topic model, biterm topic model, dynamic word embedding, document embedding, keyness analysis), which had no or only occasionally been used in domestic social research. These are discussed in more detail in the scientific results below.
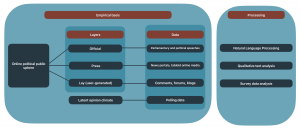
One of the biggest challenges of the project was the collection of the corpus. According to the basic concept of the research, three levels of public (political, media and lay public) were distinguished and the corpora were collected accordingly. The creation of the media corpus was the most human resource-intensive task, with four Master’s students and three junior researchers working on it from the first year of the project, in professional cooperation with the Centre for Digital Humanities (ELTE DH) of ELTE University of Applied Sciences. The corpus was built following the methodology developed by Indig and co-authors (Indig B. et al, 2020), under the guidance of Árpád Knap, one of the authors of the referenced work. The specificity of corpus construction is that the corpus was carefully metadata-edited and archival-edited, solving technical challenges such as different medium structure, filtration of duplicates or multiple page’s structure. The task was completed by mid-2022, and the corpus became part of a repository maintained by ELTE DH and accessible for academic research on the Zenodo platform (https://zenodo.org).
To process the corpus, we needed a standardized cleaning and pre-processing pipeline developed for Hungarian. The stages of this process were: character standardization, filtering of the texts for certain aspects, cleaning and filtering of the words, word formatting and standardization of the words. For Hungarian, there are several linguistic solutions for these tasks, and after reviewing them, we have created a convention pipeline in Python on GitHub, to which we provide access on request.
Scientific results
Methodological results
Topic: Using NLP to research political polarisation in general
Related publication: Németh, Renáta (2023): A scoping review on the use of natural language processing in research on political polarization: trends and research prospects. Journal of Computational Social Science
The article provided the methodological basis for the project. It summarised studies published on the topic since 2010 to clarify how the NLP research paradigm conceptualises and operationalises political polarisation, looking for patterns to follow and trying to identify research white spots that our research might aspire to fill.
Topic: How to measure political polarisation? Proposing a linguistically grounded metric
Related Publication: Buda Jakab, Németh Renáta, Simonovits Bori, Simonovits Gábor (2022): The language of discrimination: assessing attention discrimination by Hungarian local governments. Language Resources and Evaluation
In our project, we considered polarization as a supervised machine learning problem, and investigated the effectiveness of predicting the author’s party affiliation based on, for example, speeches of members of parliament belonging to different parties, and this effectiveness also served as a general measure of polarization. In this pilot work, we used the text of municipal office emails (i.e. not yet political texts) written to (putative) Roma and non-Roma clients to show that differences in textual data can be detected automatically without human coding, and that machine learning can detect distinguishing features that human coders might not recognise. Our study has also attempted to perform a task of primary importance in polarization research, the interpretation of models, i.e., the identification of the linguistic features that the algorithm recognizes behind the distinction.
Topic: How can changes in the meaning of political expressions be investigated? An NLP-based solution proposal
Related publication: Rakovics Zsófia (2022): Temporal Positive Pointwise Mutual Information (TPPMI) időbeli szóbeágyazási modell alkalmazásában rejlő lehetőségek demonstrálása – A miniszterelnöki beszédek szavainak jelentésváltozása. [Demonstrationg potentials in the application of the Temporal Positive Pointwise Mutual Information (TPPMI) temporal word-embedding model – The change in meaning of the words in the prime ministers’ speeches] In: Feledy, A. & Egle, B. (Eds.), Van új a nap alatt: Az ELTE Angelusz Róbert Társadalomtudományi Szakkollégium konferenciájának tanulmánykötete [There is something new under the sun: Proceedings of the conference of the Angelusz Róbert College for Advanced Studies in Social Sciences at ELTE.
The author is currently working with Márton Rakovics on an international publication to present the results.
One of the main issues of our project, the method developed to investigate the changing meanings of political concepts, is described. It proposes to quantitatively investigate semantic dynamics by means of a temporal word embedding model developed for this purpose.
Topic: Sociological application challenges of supervised machine learning
Related publication: Németh, Renáta (2021): A felügyelt gépi tanulás kihívásai a szociológiai alkalmazásokban. [The challenges of supervised machine learning in sociological applications] Metszetek – Társadalomtudományi folyóirat, Big Data special issue.
The sociological applications of supervised machine learning, already well demonstrated in industrial/business applications, raise specific questions. The reason for this specificity is that in these applications the algorithm is responsible for learning complex concepts. This paper provides a summary of these challenges and possible solutions.
Topic: the integration of NLP into sociological methodology
Related publication: Németh, Renáta; Koltai, Júlia (2023): Natural language processing: The integration of a new methodological paradigm into sociology. Intersections: East European Journal of Society and Politics
Integrating NLP into sociology faces a number of challenges. NLP has been institutionalised outside sociology, while sociology has built its expertise on its own research methods. Another challenge is epistemological: it relates to the validity of digital data and the different perspectives associated with predictive and causal approaches. In our paper we have offered some possible solutions to these challenges.
Results in content
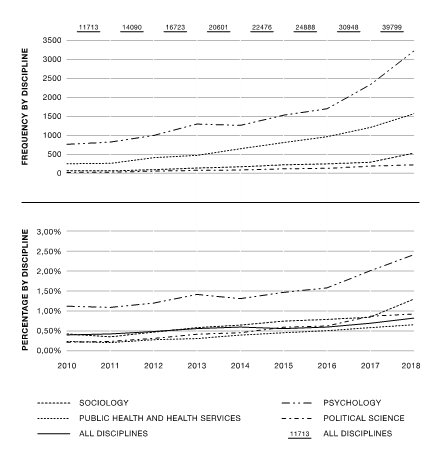
In the research, we attempted to map the discourses in the official political, media and social media layers of the Hungarian public between 2000 and 2020 (see figure below).
A sociological analysis of the official, media-based and lay online public sphere using automated text analytics and critical discourse analysis
A research project supported by NKFIH (National Research, Development and Innovation Office) (K-134428)
Period of support: December 2020-December 2023
Date of the report: 20. December 2023.
Principal Investigator: Renáta Németh
Participants: Ildikó Barna, Jakab Buda, Eszter Katona, Árpád Knap, Tibor Pólya (HUN-REN TTK), Márton Rakovics, Zsófia Rakovics, Domonkos Sik, Emese Tóth, Anna Unger
Summary
The public sphere is the cornerstone of modern representative democracies: it is responsible not only for providing the voters with the necessary information for a deliberate vote but also to keep the administrative system in check not solely from a legal but also from a moral standpoint. In this sense, the prospect of averting those potential distortions and crises which may emerge in democratic systems depend on the quality of the public sphere (Habermas 1975, 1998). The emergence of the online public sphere overlaps with several waves of significant political transformations and reconfigurations of the political field in Hungary. Therefore, Hungary is a particularly rich context for this research.
The research provided a sociological analysis of the public discourse of the last two decades at different levels of the Hungarian public sphere – the official political sphere, the online media and the online lay public – focusing on a few key aspects, mainly based on the automated analysis of large text corpora. We have explored the linguistic representation of political polarization, the discourse of memory politics, collective identity issues and certain public policy topics.
Digital data produced in online public spheres are primarily textual. Such data require analytical tools, which became accessible only recently with the emergence of the field of Natural Language Processing (NLP) capable of processing large-scale textual data in a systematic, automated way. These innovative tools provide suitable depth in results for sociology (Németh and Koltai, 2020). Sociology will exploit the potential of these changes if it can renew its research culture while preserving its critical reflections. Hence it was our mission to plan a research that shows how NLP can be integrated in an organic way into the toolbox of traditional sociological methods. To reach this aim, we plan to combine automated text analytics with not only qualitative discursive analysis but also traditional quantitative statistical methods.
The project used or further developed several tools of NLP (structural topic model, biterm topic model, dynamic word embedding, document embedding, keyness analysis), which had no or only occasionally been used in Hungarian sociological research. NLP was integrated into the traditional text analytical tools of Sociology and combined with qualitative tools. According to our results, these methods can successfully measure political polarization and map the dynamics of relations between actors in the public sphere, the framing of topics in public discourse, changes in framing, or changes in the meaning of certain key concepts.
We consider our research to has been successfully completed in in terms of both the research results and publications, the implemented innovative methodological approaches and the established new research collaborations Below is a summary dated December 2023.
Publications, disseminations
The output of the research is several times higher than what was committed in the application. 48 scientific publications have been produced (with a total impact factor of 9.6), of which 11 have been published in peer-reviewed journals and 4 are under review. Of these, 7 international articles (3 D1 and 3 Q2), 4 national articles, 10 international conference presentations. One of the D1 articles of the project (authored by Barna-Knap) won the Polányi Prize for the best sociological article of the year in 2023, awarded by the Hungarian Sociological Association.
The list at the bottom of this page provides only a selection of the four dozen publications (also identifiable in MTMT), with only the final, highest-ranking publication from each sub-project. A special issue of the journal Intersections on the topic of our research (‘Text as data – Eastern and Central European political discourses from the perspective of computational social science’), initiated and partly guest-edited by members of our research team, is scheduled to appear in 2024, with four articles from the research under review.
We have also organised a conference and several conference sessions. In the summer of 2021, Ildikó Barna and Renáta Németh organised a session at the international conference of the ISA RC33 committee (‘Natural Language Processing: a New Tool in the Methodological Tool-Box of Sociology’), where we also presented our research. In October 2023, our members (Zsófia Rakovics, Eszter Katona, Emese Tóth) organized a session at the Hungarian Sociological Society’s Annual Meeting entitled ‘Natural Language Processing in the Social Sciences’, where we also presented our research.
We have reached out to the wider public in various forums, and besides our website and Facebook page, we have held six educational presentations: we gave a presentation and participated in a roundtable at the Night of Researchers, the Mihály Táncsics Talent College and the Róbert Angelusz Social Sciences College, we participated in the ConTEXT business conference, and Márton Rakovics gave a lecture at the invitation of the University of Osijek at the Faculty of Law in September 2023.
Research recruitment education, new scientific relationships
We were also able to use the research in the training of young researchers: 3 PhD theses were successfully advertised, with Jakab Buda, Zsófia Rakovics, Emese Tóth joining the research, details of their topics can be found below. Four doctoral and one postdoctoral New National Excellence Program (now University Research Scholarship Program, EKÖP) supported research, theses and TDK (Scientific Student Council) theses were linked to the project. We also integrated the research methodology and results into our taught courses.
As the project has progressed, collaborations have been established that have allowed for deeper analysis as a new interdisciplinary research direction. Thus, we worked with social psychologist Bori Simonovits, political scientists Gábor Simonovits and Anna Unger, human geographer Péter Balogh, religious researcher András Máté-Tóth and narrative psychologist Tibor Pólya as co-authors.
Innovative methodological solutions
Another important output of the project is the testing and introduction of innovative methodological approaches. Several approaches and NLP tools were used and partly developed (structural topic model, biterm topic model, dynamic word embedding, document embedding, keyness analysis), which had no or only occasionally been used in domestic social research. These are discussed in more detail in the scientific results below.
One of the biggest challenges of the project was the collection of the corpus. According to the basic concept of the research, three levels of public (political, media and lay public) were distinguished and the corpora were collected accordingly. The creation of the media corpus was the most human resource-intensive task, with four Master’s students and three junior researchers working on it from the first year of the project, in professional cooperation with the Centre for Digital Humanities (ELTE DH) of ELTE University of Applied Sciences. The corpus was built following the methodology developed by Indig and co-authors (Indig B. et al, 2020), under the guidance of Árpád Knap, one of the authors of the referenced work. The specificity of corpus construction is that the corpus was carefully metadata-edited and archival-edited, solving technical challenges such as different medium structure, filtration of duplicates or multiple page’s structure. The task was completed by mid-2022, and the corpus became part of a repository maintained by ELTE DH and accessible for academic research on the Zenodo platform (https://zenodo.org).
To process the corpus, we needed a standardized cleaning and pre-processing pipeline developed for Hungarian. The stages of this process were: character standardization, filtering of the texts for certain aspects, cleaning and filtering of the words, word formatting and standardization of the words. For Hungarian, there are several linguistic solutions for these tasks, and after reviewing them, we have created a convention pipeline in Python on GitHub, to which we provide access on request.
Scientific results
Methodological results
Topic: Using NLP to research political polarisation in general
Related publication: Németh, Renáta (2023): A scoping review on the use of natural language processing in research on political polarization: trends and research prospects. Journal of Computational Social Science
The article provided the methodological basis for the project. It summarised studies published on the topic since 2010 to clarify how the NLP research paradigm conceptualises and operationalises political polarisation, looking for patterns to follow and trying to identify research white spots that our research might aspire to fill.
Topic: How to measure political polarisation? Proposing a linguistically grounded metric
Related Publication: Buda Jakab, Németh Renáta, Simonovits Bori, Simonovits Gábor (2022): The language of discrimination: assessing attention discrimination by Hungarian local governments. Language Resources and Evaluation
In our project, we considered polarization as a supervised machine learning problem, and investigated the effectiveness of predicting the author’s party affiliation based on, for example, speeches of members of parliament belonging to different parties, and this effectiveness also served as a general measure of polarization. In this pilot work, we used the text of municipal office emails (i.e. not yet political texts) written to (putative) Roma and non-Roma clients to show that differences in textual data can be detected automatically without human coding, and that machine learning can detect distinguishing features that human coders might not recognise. Our study has also attempted to perform a task of primary importance in polarization research, the interpretation of models, i.e., the identification of the linguistic features that the algorithm recognizes behind the distinction.
Topic: How can changes in the meaning of political expressions be investigated? An NLP-based solution proposal
Related publication: Rakovics Zsófia (2022): Temporal Positive Pointwise Mutual Information (TPPMI) időbeli szóbeágyazási modell alkalmazásában rejlő lehetőségek demonstrálása – A miniszterelnöki beszédek szavainak jelentésváltozása. [Demonstrationg potentials in the application of the Temporal Positive Pointwise Mutual Information (TPPMI) temporal word-embedding model – The change in meaning of the words in the prime ministers’ speeches] In: Feledy, A. & Egle, B. (Eds.), Van új a nap alatt: Az ELTE Angelusz Róbert Társadalomtudományi Szakkollégium konferenciájának tanulmánykötete [There is something new under the sun: Proceedings of the conference of the Angelusz Róbert College for Advanced Studies in Social Sciences at ELTE.
The author is currently working with Márton Rakovics on an international publication to present the results.
One of the main issues of our project, the method developed to investigate the changing meanings of political concepts, is described. It proposes to quantitatively investigate semantic dynamics by means of a temporal word embedding model developed for this purpose.
Topic: Sociological application challenges of supervised machine learning
Related publication: Németh, Renáta (2021): A felügyelt gépi tanulás kihívásai a szociológiai alkalmazásokban. [The challenges of supervised machine learning in sociological applications] Metszetek – Társadalomtudományi folyóirat, Big Data special issue.
The sociological applications of supervised machine learning, already well demonstrated in industrial/business applications, raise specific questions. The reason for this specificity is that in these applications the algorithm is responsible for learning complex concepts. This paper provides a summary of these challenges and possible solutions.
Topic: the integration of NLP into sociological methodology
Related publication: Németh, Renáta; Koltai, Júlia (2023): Natural language processing: The integration of a new methodological paradigm into sociology. Intersections: East European Journal of Society and Politics
Integrating NLP into sociology faces a number of challenges. NLP has been institutionalised outside sociology, while sociology has built its expertise on its own research methods. Another challenge is epistemological: it relates to the validity of digital data and the different perspectives associated with predictive and causal approaches. In our paper we have offered some possible solutions to these challenges.
Results in content
In the research, we attempted to map the discourses in the official political, media and social media layers of the Hungarian public between 2000 and 2020 (see figure below).
Related doctoral researches
Doctoral student: Zsófia Rakovics
Advisors: Renáta Németh, PhD and Domonkos Sik, PhD
Analysing the discourse of sustainability in the triad of political publicity, online media platforms and the lay public
Doctoral student: Emese Tóth
Advisor: Balázs János Kocsis, PhD
Doctoral student: Jakab Buda
Advisor: Renáta Németh, PhD
Publications published in the framework of the project (selected list)
Csomor, Gábor; Simonovits, Borbála; Németh, Renáta: Hivatali diszkrimináció?: Egy online terepkísérlet eredményei, Szociológiai Szemle, 2021
Katona, Eszter, Németh, Renáta: Automatizált szöveganalitika a korrupció kutatásában, SOCIO.HU: TÁRSADALOMTUDOMÁNYI SZEMLE, 2021
Barna, Ildikó; Knap, Árpád: Analysis of the Thematic Structure and Discursive Framing in Articles about Trianon and the Holocaust in the Online Hungarian Press Using LDA Topic Modelling., NATIONALITIES PAPERS, 2022
Boda Zsuzsanna, Rakovics Zsófia: Orbán Viktor 2010 és 2020 közötti beszédeinek elemzése: A migráció témájának vizsgálata, Szociológiai Szemle, 2022
Buda Jakab, Németh Renáta, Simonovits Bori, Simonovits Gábor: The language of discrimination: assessing attention discrimination by Hungarian local governments, Language Resources and Evaluation, 2022
Buda, Jakab ; Simonovits, Bori ; Németh, Renáta: Hivatali diszkrimináció? – Figyelemdiszkrimináció mérése természetes nyelvfeldolgozással, Konferencia előadás, Szöveg.Gép.Társadalom – Társadalmi viszonyok megragadása szöveges adatok számítógépes elemzésével., Az ELTE Reserach Center for Computational Social, 2022
Knap Árpád, Bartha Diána, Barna Ildikó: Trianon és a holokauszt emlékezetpolitikai jellegzetességeinek elemzése természetesnyelv-feldolgozás használatával, Szociológiai Szemle, 2022
Knap, Árpád ; Tóth, Tímea Emese ; Barna, Ildikó: Érzelmek megjelenése a Trianoni békeszerződéssel és a holokauszttal kapcsolatos cikkek szóbeágyazásaiban, az érzelmek automatizált detektálásának lehetséges eszközei, Konferencia előadás, Szöveg.Gép.Társadalom – Társadalmi viszonyok megragadása szöveges adatok számítógépes elemzésével., Az ELTE Reserach Center for Computational Social, 2022
Németh Renáta: A szakterületi tudás (domain knowledge) szerepe az adattudomány társadalomkutatási alkalmazásaiban, In: Loncsák, Noémi; Szabó-Tóth, Kinga (szerk.) Szociológiai tudás és közjó : absztraktkötet. Miskolc, Magyarország : Magyar Szociológiai Társaság (2022) 247 p. pp. 158-15, 2022
Németh Renáta: Nyelvi polarizáció kutatása NLP-vel: módszertani kihívások (általánosíthatóság, oksági tévkövetkeztetés), Gép.Társadalom – Társadalmi viszonyok megragadása szöveges adatok számítógépes elemzésével., Az ELTE Research Center for Computational Social Science konferenciája. 2022.
Rakovics Zsófia: Migrációs diskurzusok elemzése a parlamenti felszólalások alapján, Magyar Szociológiai Társaság (MSZT) Vándorgyűlés, Szociológiai tudás és közjó, Miskolci Egyetem, 2022. október 14-15., 2022
Rakovics Zsófia és Rakovics Márton: Parlamenti felszólalások elemzése dokumentumbeágyazással. Szöveg.Gép.Társadalom – Társadalmi viszonyok megragadása szöveges adatok számítógépes elemzésével, Szöveg.Gép.Társadalom – Társadalmi viszonyok megragadása szöveges adatok számítógépes elemzésével., Az ELTE Reserach Center for Computational Social Science konferenciája, 2022
Rakovics, Zsófia; Rakovics, Márton: Semantic evolution of words in Hungarian PM Viktor Orbán’s speeches using a temporal word embedding model focusing on the issue of migration, Konferencia megjelenés (poszter) a 8. Nemzetközi Számítógépes Társadalomtudomány Konferencián (8th International Conference on Computational Social Science IC2S2). 2022., 2022
Sik Domonkos: A poiesis autonómiája – a társadalmi struktúrák és a diszkurzív lehetőségterek kölcsönhatása, A társadalomelmélet alapkérdései – konferencia a Nemzeti Közszolgálati Egyetemen, 2022. november 3-4., 2022
Tóth Tímea Emese: Analysis of the Twitter Discourse on Sustainability Using Natural Language Processing, Education of Economists & Managers, 2022
Tóth Tímea Emese: A fenntarthatósággal kapcsolatos Twitter-diskurzus elemzése a természetes nyelvi feldolgozás módszerével, “Kit érdekel még a szociológia?” – konferencia, Társadalomtudományi Kutatóközpont, 2022.06.03., 2022
Tóth Tímea Emese: Hogyan definiálta újra a COVID-19 pandémia a fenntarthatóság fogalmát a laikus nyilvánosságban? Narratívák és kommunikációs stratégiák, Eötvös Loránd Tudományegyetem. 2022.08.31., 2022
Tóth Tímea Emese: Minden, amit a fenntarthatóságról és klímaváltozásról tudni akartál, de nem merted megkérdezni, Táncsis Mihály Tehetséggondozó Kollégium Budapest. 2022.03.09., 2022
Barna, Ildikó; Németh, Renáta; Pólya, Tibor; Berbekár, Réka: Examining the Different Political Sides’ Memorialization of Using Tools of Natural Language Processing and Narrative Psychology, XX. ISA World Congress of Sociology, 2023. jún. 25-júl. 1, 2023
Katona, Eszter; Németh, Renáta: Carpathian Basin-related topics in Hungarian parliamentary speeches. A concept related to Hungary’s self-definition, CENTRAL Workshop: Notion and Construction of Victimhood in Central East and Southeast Europe. 2023. február 8-10. Bécs, 2023
Máté-Tóth, András; Rakovics, Zsófia: The discourse of christianity in Viktor Orbán’s rhetoric, Religions, 2023
Németh Renáta: A scoping review on the use of natural language processing in research on political polarization: trends and research prospects, Journal of Computational Social Science , 25 p., 2023
Németh Renáta, Katona Eszter, Balogh Péter, Rakovics Zsófia, Unger Anna: What else comes with a geographical concept beyond geography? Discourses related to the Carpathian Basin in the Hungarian Parliament, bírálat alatt, 2023
Németh Renáta, Rakovics Zsófia: A természetesnyelv-feldolgozás néhány szociológiai alkalmazásáról, SciComp 2023 konferencia. Budapest, 2023. november 7-8., 2023
Németh, Renáta; Barna, Ildikó; Pólya, Tibor: Az NLP kísérleti kombinálása narratív pszichológiai gépi elemzővel – A trianoni békeszerződés a magyar online médiában a 100. évfordulón, A Magyar Szociológiai Társaság 2023. évi vándorgyűlése, Corvinus Egyetem, Budapest, 2023., 2023
Németh, Renáta; Buda, Jakab; Simonovits, Bori: The Language of Discrimination: Assessing Attention Discrimination By Hungarian Local Governments Using Machine Learning, XX. ISA World Congress of Sociology, 2023. jún. 25-júl. 1., 2023
Németh, Renáta; Buda, Jakab; Simonovits, Bori: Who knows it better? The task of detecting discrimination using human coding vs. text mining, EuMePo (European Memory Politics) Jean Monnet Network Conference, Budapest, 2023. június 15., 2023
Németh, Renáta; Koltai, Júlia: Natural language processing: The integration of a new methodological paradigm into sociology, INTERSECTIONS: EAST EUROPEAN JOURNAL OF SOCIETY AND POLITICS 9: 1 pp. 5-22., 2023
Rakovics Zsófia: Memory politics in the Hungarian Parliament, CENTRAL workshop: Notion and Construction of Victimhood in Cenral East and Southeast Europe. Vienna, 8-10 February, 2023, 2023
Rakovics Zsófia: Investigating language- and political polarization through two decades of parliamentary speeches, XX. ISA World Congress of Sociology. 25 June – 1 July, 2023, 2023
Rakovics Zsófia: Investigating dynamic social networks of politicians constructed by the similarity of their speeches, XX. ISA World Congress of Sociology. 25 June – 1 July, 2023, 2023
Rakovics Zsófia: Szóbeágyazások és nagy nyelvmodellek társadalomtudományi alkalmazásának példái, conTEXT 2023 – Change the game? Budapest, CEU, 2023. november 14., 2023
Rakovics Zsófia, Barna Ildikó: The stages of Jobbik becoming a people’s party Analyzing the parliamentary speeches of Jobbik and the dynamic network of its politicians between 2010 and 2020, bírálat alatt, 2023
Rakovics Zsófia, Rakovics Márton: Language- and political polarization of parliamentary speeches between 1998-2020, 9th International Conference on Computational Social Science. Copenhagen, 17-20 July, 2023, 2023
Sik Domonkos, Rakovics Zsófia, Németh Renáta: Towards a culture of disrespect – topic modeling Hungarian parliamentary discourses, bírálat alatt, 2023
Sik, Domonkos: Populist Juggling with Fear: The Case of Hungary, EAST EUROPEAN POLITICS AND SOCIETIES 37 : 4 pp. 1291-1313. , 23 p, 2023
Szalay Áron, Rakovics Zsófia: Tuned to Fear – Analyzing Viktor Orbán’s State of the Nation Addresses, focusing on the enemy images identified in the National Consultation, bírálat alatt, 2023
Tóth Tímea Emese: Hogyan kapcsolódik a koronavírus és a fenntarthatóság az online média kommunikációjában?, Táncsics Mihály Tehetséggondozó Kollégium. Budapest. 2023.04.25., 2023
Tóth Tímea Emese: A fenntarthatóság politikai polarizáció által keretezett narratív lehetőségei az online média felületeken, Eötvös Loránd Tudományegyetem. 2023.08.31., 2023
Tóth Tímea Emese: Hogyan hatott a koronavírus-járvány a fenntarthatósági diskurzusra?, Magyar Szociológiai Társaság Éves Vándorgyűlése 2023. Válságról válságra. Budapest. 2023.11.18., 2023
Verebes Ingrid, Rakovics Zsófia: A család diskurzusának alakulása az 1998-2020 közötti parlamenti felszólalásokban, MSZT 2023. évi vándorgyűlés. Budapest, BCE, 2023. november 17-18., 2023